Pandas中loc,iloc,ix的使用
使用 iloc 从DataFrame中筛选数据
iloc 是基于“位置”的Dataframe的操作,即主要基于下标的操作
简单使用
Pandas中的 iloc 是用基于整数的下标来进行数据定位/选择
iloc 的语法是 data.iloc[<row selection>, <column selection>], iloc 在Pandas中是用来通过数字来选择数据中具体的某些行和列。你可以设想每一行都有一个对应的下标(0,1,2,…),通过 iloc 我们可以利用这些下标去选择相应的行数据。同理,对于行也一样,想象每一列也有对应的下标(0,1,2,…),通过这些下标也可以选择相应的列数据。
在iloc中一共有 2 个 “参数” -行选择器 和 -列选择器,例如:
1 | # 使用DataFrame 和 iloc 进行单行/列的选择 |
行列混合选择
iloc 同样可以进行和列的混合选择,例如:
1 | # 使用 iloc 进行行列混合选择 |
使用 iloc 注意以下两点:
如果使用iloc只选择了单独的一行会返回 Series 类型,而如果选择了多行数据则会返回 DataFrame 类型,如果你只选择了一行,但如果想要返回 DataFrame 类型可以传入一个单值list,具体例子看图:
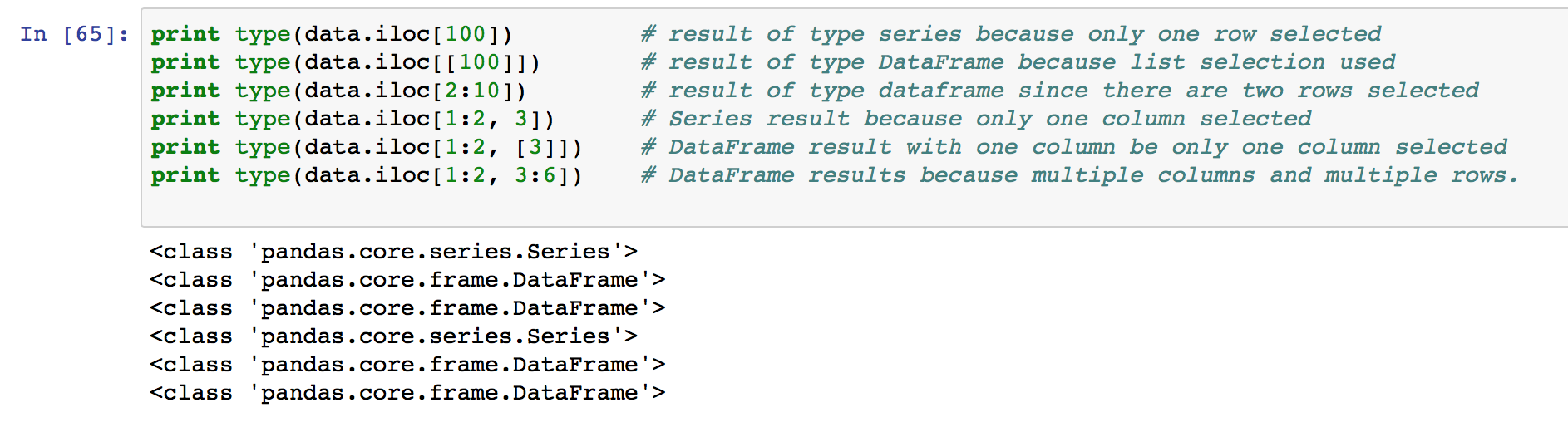
当你使用 [1:5] 这种语法对数据进行切片的时候,要注意只选择了 1,2,3,4 这 4 个下标,而 5 并没有被包括进去,即使用[x:y]选择了下标从 x 到 y-1 的数据
实际工作中,其实很少用到 iloc ,除非你想选择第一行( data.iloc[0] ) 或者 最后一行( data.iloc[-1] )
使用 loc 从DataFrame中筛选数据
可以在以下2中情况下使用 ioc:
- 使用 基于标签(列头)的下标的 查找
- 使用 boolean / 有条件的 查找
使用 loc 的语法和 iloc 一样:data.loc[<row selection>, <column selection>]
使用基于标签(列头)的下标数据选择
使用 loc 进行数据选择是基于下标的(如果有的话),可以使用 df.set_index() 来设置下标, loc 方法直接通过下标来选择行。
例如将”last_name”这一列设置为下标:
1 | data.set_index("last_name", inplace=True) |
效果如图: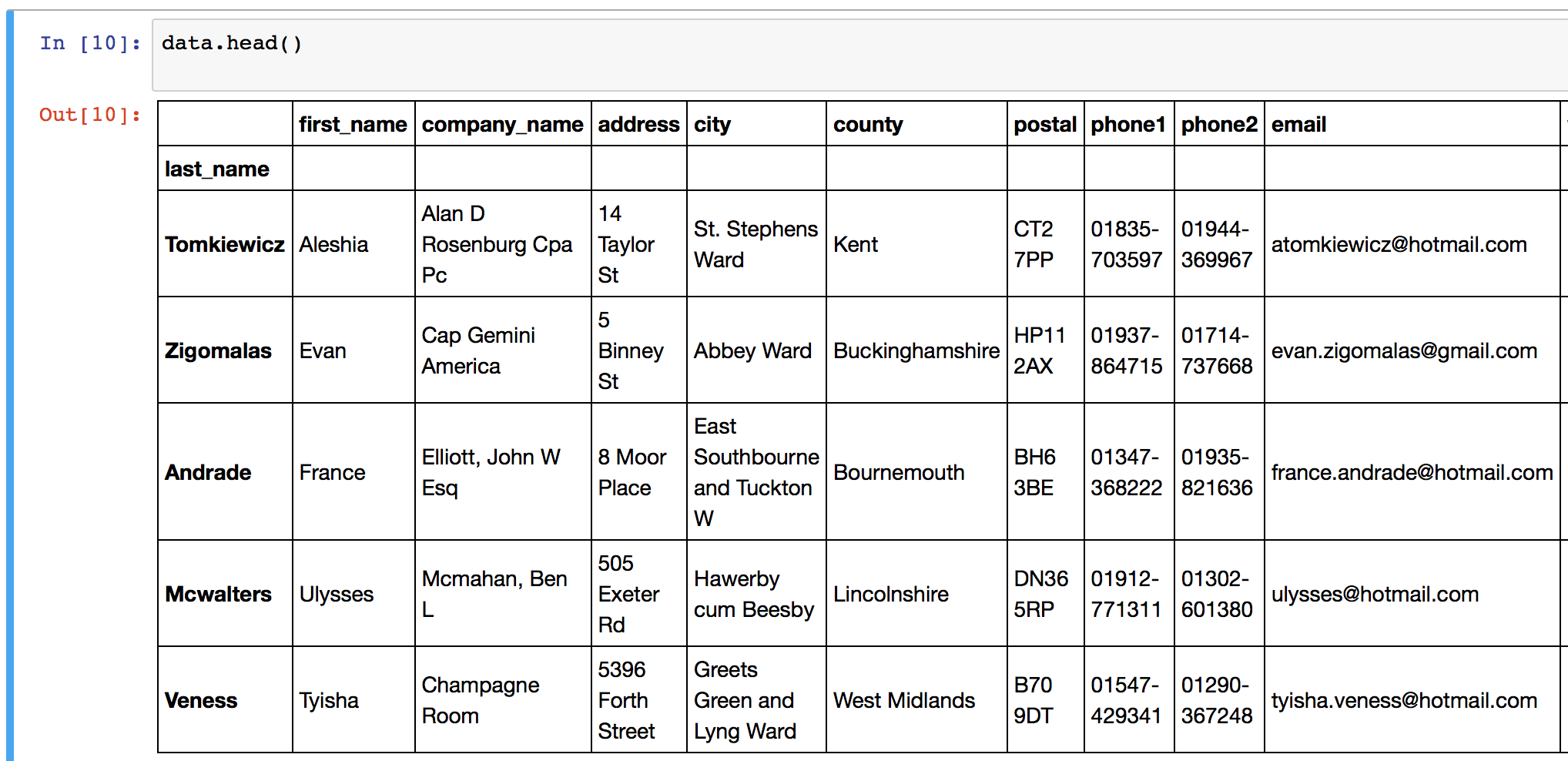
现在我们已经将下标设置为”last_name”,这样我们就可以根据”last_name”选择不同的数据了,使用 data.loc[<label>]
同样的可以查找单个值或者多个值,例子如图: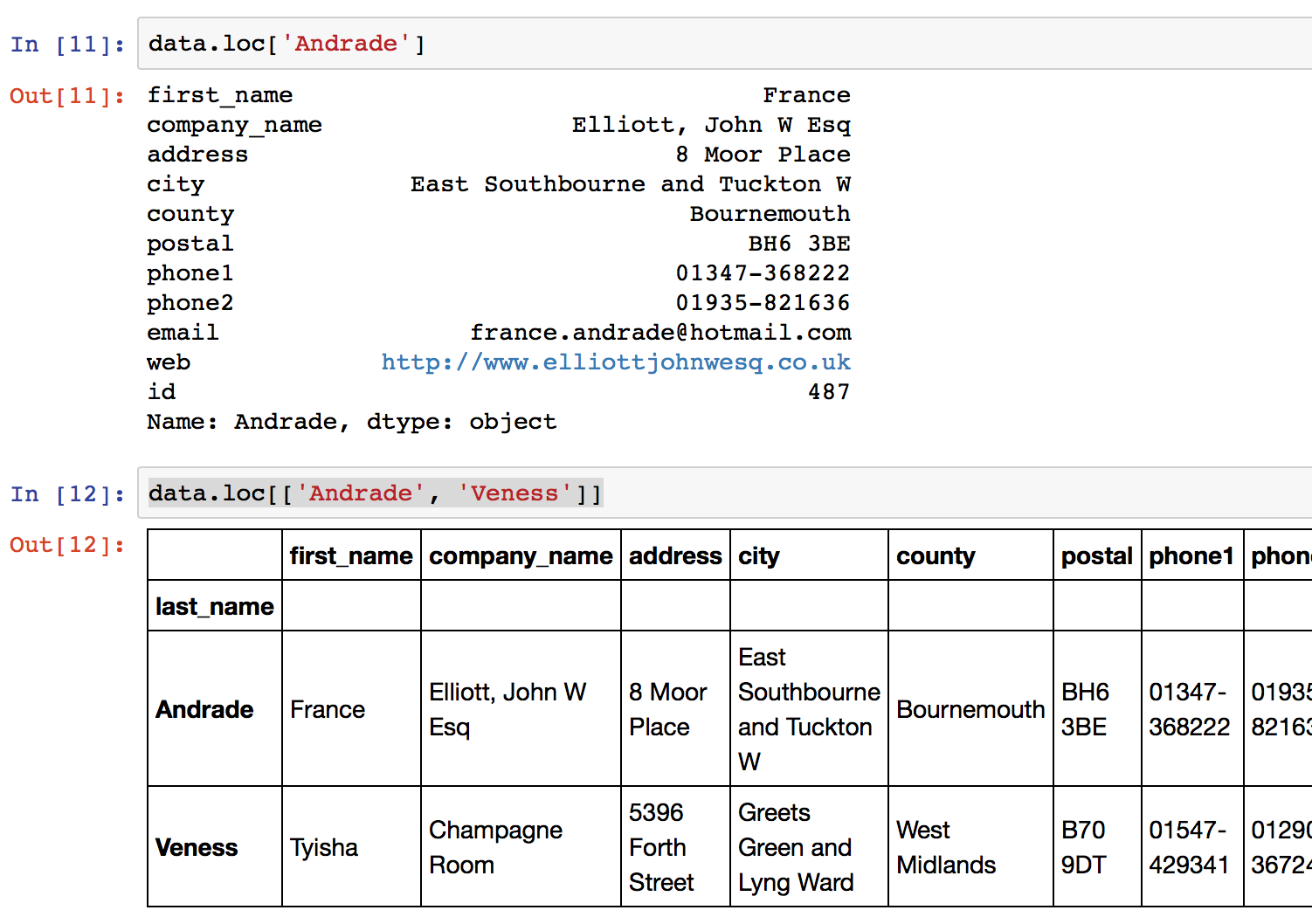
注意,第一个样例代码返回的是 Series 类型,而第二个样例代码返回的是 DataFrame 类型,同样你也可以通过传递一个单值list来返回一个 DataFrame 类型的数据
当然也可以使用 loc 对列进行选择,同时可以选择对列使用 “ : “进行切片选择,效果如图: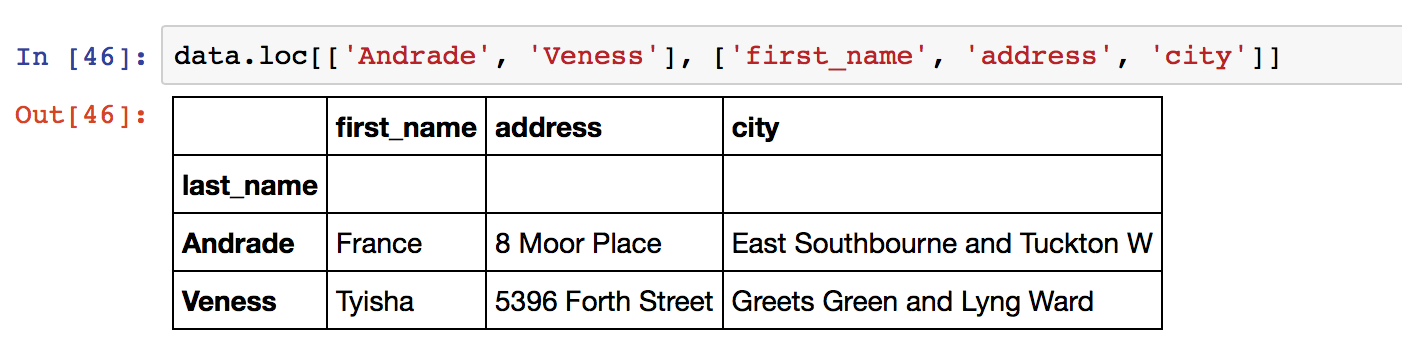
同时,你还可以使用 “ : “ 对下标进行切片选择,例如 data.loc['Bruch':'Julio'] 会选择从下标为’Bruch’到下标为’Julio’ 的所有行,例如:
1 | # 选择下标值为'Andrade' 和 'Veness',并且从'city'到'email'的所有列 |
注意:最后一行代码:data.loc[487] 不等价于 data.iloc[487], 前者是选择 ‘id’ = 487 的行,而后者是选择第488行,DataFrame的索引可以是数字顺序的,也可以是字符串或多值的。
使用Boolean / 逻辑判断选择数据
使用 boolean 数组进行条件选择是较为常用的手段,使用boolean下标或者逻辑表达式,你可以传递给 loc 一个值为 True/False 的Series或者数组来选择那些 Series或者数组中值为 True 的行。
较多情况下,语句 data["first_name" == 'Antonio'] 会返回一个值为 True/False 的 Series 类型数据,其中 “True” 代表这一行中的 “first_name” 值为 “Antonio”,这些 boolean数组可以直接如图所示传递给 loc 方法:
和之前一样,可以传递给 loc 第2个”参数”用来选择某些列,可以是列举的列名,也可以是用 “ : “ 切片的连续列,如图:
同样要注意:如果只选择了单独的一列,返回的是 Series 类型,同样传递一个单值list可以返回 DataFrame 类型,如图:
通过以下代码可以很好的理解 loc 的使用:
1 | # 选择 first_name 为Antonio,并且从 'city' 到 'email'的所有列 |
顺便说一下Pandas中 map(), apply() 和 applymap()的区别
map()是 Series 中的函数,DataFrame 中是没有map()的,map()将函数应用于Series中的每一个元素apply()和applymap()是 DataFrame 中的函数,而在Series中是没有的。他们的区别在于:apply()将函数作用于DataFrame中的 每一个行或者列,而applymap()会将函数作用于DataFrame中的 每一个元素。
使用 loc 修改 DataFrame 中的数据
你可以像使用 loc 查询数据那样对数据进行修改,这个操作不会返回新的数据对象而是直接在原数据上进行修改。通过这个操作,你可以根据不同的情况对数据进行修改:
1 | # 修改 'id' > 2000 的数据中的 'first_name' 为 "John" |
使用 ix 进行选择
现在pandas官方已经不推荐使用 ix 进行选择了,并且将会在 0.20.1版本从Pandas中丢弃

