刚刚接触深度学习,以目标检测为入手,本文主要以yolov3的Keras实现为主线,穿插入yolov3的论文思想,也是记录自己的学习过程。
写在前面
- 首先感谢@qqwweee以及各位contributors完美的用Keras实现了yolov3,本文也是以此项目进行yolov3的源码解读学习,repo:https://github.com/qqwweee/keras-yolo3
- 文章内容大部分也是借鉴了@SpikeKing 对此源码的解读,讲解的非常详细,本文只是在此之上加入了自己学习过程中的一些想法,大家有兴趣的可以直接阅读,repo:https://github.com/SpikeKing/keras-yolo3-detection
- 由于源码比较复杂,作者也只是刚刚接触yolov3,能力有限,所有会有部分内容不能完整的照顾到,如果没有能帮助到您在此表示抱歉。
阅读建议
由于整个项目包含了对yolov3的算法的全部实现,主要分为核心算法实现以及使用相关代码实现,所以整体内容较为庞大,建议大家先按照自己的侧重进行阅读。如果侧重 使用 :建议从使用章节开始阅读,如果侧重 算法学习 :建议从核心算法实现开始阅读。
项目结构
我们可以从项目的包结构中对算法实现进行简单的探索:
├─font
├─model_data
├─yolo3
│ └─pycache
├─yolo.py
├─train.py
├─yolo_video.py
└─pycache
font 目录下包含一些字体,核心实现还是在 model_data 和 yolo3 这两个文件夹
model_data 文件夹中包含了coco数据集和voc数据集的相关说明文件,例如对数据集聚类后生成的anchors文件,数据集的类别说明文件,后期需要使用的 yolo 的权重文件也会放在这
yolo3 文件夹中包含了算法实现的核心文件: model.py 和 util.py, model.py 主要实现算法框架,util.py 主要封装一些实现需要的功能
train.py: 使得可以使用自己的数据集进行训练,其中就用到了核心算法
yolo.py 和 yolo_video.py : yolo.py 实现了主要的使用方面的功能,yolo_video.py 是整个项目的使用入口文件,调用了 yolo.py 中的相关函数
使用
简单开始
下载权重文件
首先模型需要训练好的权重参数才能够进行检测,可以直接下载官方已经训练好的权重参数(貌似是使用coco和voc两个数据集训练出的结果)到项目目录下
地址:https://pjreddie.com/media/files/yolov3.weights
将 .weights 文件转换为 Keras支持的 h5 权重文件
在目录下执行:
1 | python convert.py yolov3.cfg yolov3.weights model_data/yolo.h5 |
进行图片检测
可以在 https://github.com/AlexeyAB/darknet/tree/master/data 中下载你喜欢的测试图片到项目目录下,当然也可以使用自己的图片
执行:1
python yolo_video.py --image
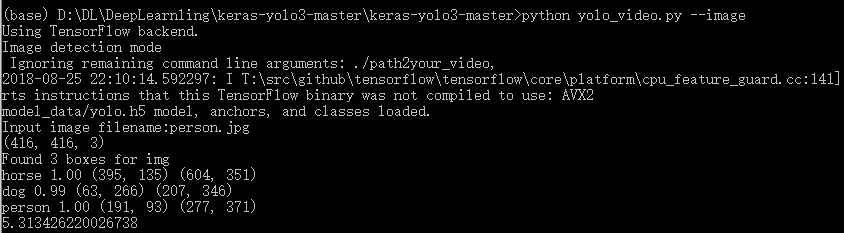
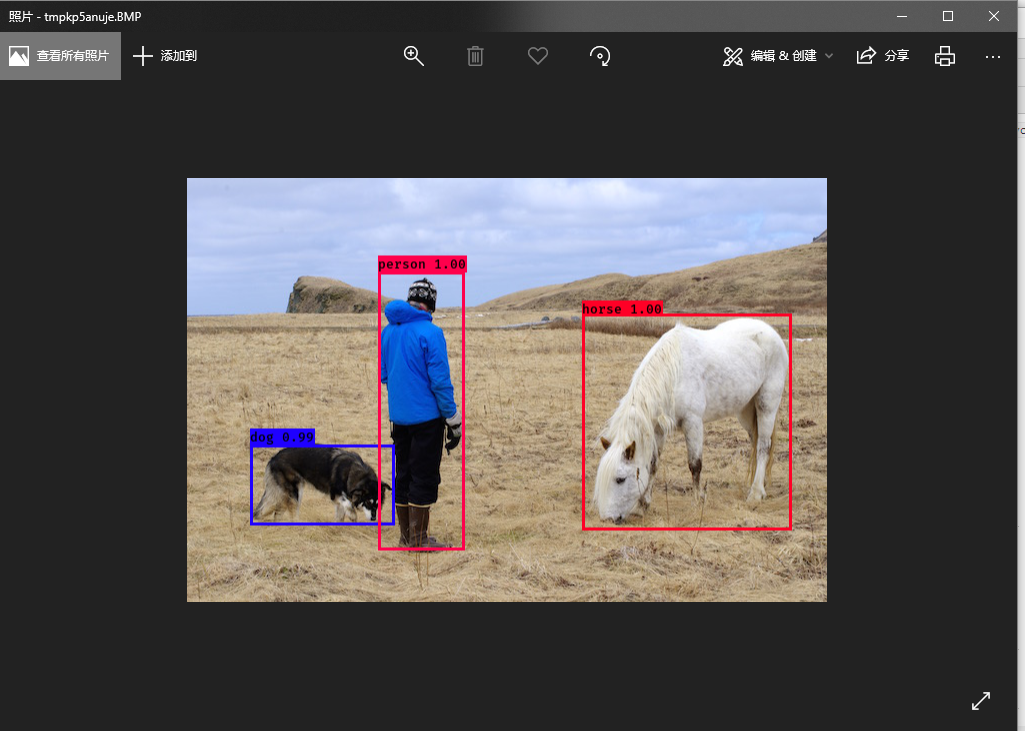
之后会要求输入需要检测的图片名称,输入图片名称之后就会出现检测结果:

利用摄像头进行视频检测
进行视频检测首先需要 CUDA 9.0+, h5py 以及 OpenCV3.x 的支持,使用 Anaconda 就可以轻松安装
同样在项目目录下执行:
1 | python yolo_video.py |
就可以利用摄像头进行视频检测,也可以加上 --input 参数变为视频检测,参数内容就是要检测的视频文件目录
源码解读
yolo_video.py
命令行参数:
--image 进入图片检测模式
--model 指定权重文件的位置,默认是 model_data/yolo.h5
--anchors 指定anchors文件位置,默认是 model_data/yolo_anchors.txt
--classes_path 指定类别文件位置, 默认是 model_data/coco_classes.txt
yolo.py
主要实现对图片中物体的检测以及得分和框的绘制
generate(self)
- 加载权重参数文件,生成检测框,得分,以及对应类别
- 利用 model.py 中的 yolo_eval 函数生成检测框,得分,所属类别
- 初始化时调用generate函数生成图片的检测框,得分,所属类别(self.boxes, self.scores, self.classes)
detect_image(self, image)
- 要求进行检测的图片尺寸大小是 32 的倍数,原因:
- 在网络中,执行的是 5次步长为2 的卷积操作,即
- 图片的默认尺寸是416 x 416,因为在最底层中的特征图(Feature Map)大小是13,所以 13 * 32 = 416
注意:
特征图和卷积核不是一个概念,特征图是指图片在进行卷积等一系列操作之后最终得到的图片,一开始喂给网络的图片也可以称作是特征图,特征图之后也会作为下一层网络的输入
,
5次步长为2的卷积操作源码:
位置:keras-yolo3-master\keras-yolo3-master\yolo3\model.py
1 | x = compose( |
detect_video
- 实现视频检测和通过摄像头实时检测的功能,利用到了OpenCV
使用自己的训练集
通过使用提供的 train.py 可以使用自己的数据集进行训练得到权重文件,从而使用自己的数据集进行检测工作
为了更方便的训练,我已经把相关的训练脚本代码放到了github上面,有兴趣的同学可以用来跑跑自己的训练集试一试,当然也可以使用原作者的 train.py 来训练,如果使用 train.py 可以参考 train.py 解读
go right ahead ~
train.py 解读
训练需要指定
- 训练数据集的标注文本
- 权重文件、训练日志输出路径:log_dir
- 类别说明文件
- 聚类好的anchors文件
创建模型的时候,默认会预加载 model_data 文件夹下的权重文件
默认将输入的训练图片转变为 input_shape(默认:416 x 416) 的格式
具体转变的过程我看的也不是很明白,但输出一定是 input_shape 的格式,代码如下:
1 | # 文件路径:./yolo3/utils.py get_random_data函数中 |
然后将训练的数据进行打乱(shuffle),交叉验证的默认比例是 10%
第一个阶段只训练最后的3个输出层
第二个阶段使用第一阶段的权重参数,继续训练所有的网络,进行权重的微调
- 将学习率从 1e-3 减少为 1e-4
==================================
核心算法实现
model.py 解读
model.py 是整个项目的核心,也是对yolo论文的复现,在 model.py 中定义了底层框架,实现了darknet框架(darknet_body),最后实现最终的yolo框架(yolo_body)
底层框架
DarknetConv2D(*args, **kwargs)
yolo是使用卷积神经网络进行训练,DarknetConv2D用来设置Darknet网络的参数,卷积神经网络用的是Keras的Conv2D
- kernel_regularizer:使用l2正则化 = l2(5e-4)
- 如果指定步长strides = (2,2) padding使用valid模式,否则使用same模式
DarknetConv2D_BN_Leaky(*args, **kwargs)
默认不适用bias:’use_bias’: False
然后使用 util包中的 compose函数 在卷积之后进行BatchNormalization和LeakyReLU,将这些步骤封装成一个函数
resblock_body(x, num_filters, num_blocks)
在yolo中还用到了残差网络,加入了residual blocks的思想,在yolo3的darknet网络架构图中,被一个框框起来的两个卷积网络+一个残差训练就是一个resblock_body,利用 resblock_body,可以搭建出darknet框架
源码如下:1
2
3
4
5
6
7
8
9
10
11'''A series of resblocks starting with a downsampling Convolution2D'''
# Darknet uses left and top padding instead of 'same' mode
x = ZeroPadding2D(((1,0),(1,0)))(x)
# 进行步长为 2 的卷积操作
x = DarknetConv2D_BN_Leaky(num_filters, (3,3), strides=(2,2))(x)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Leaky(num_filters//2, (1,1)),
DarknetConv2D_BN_Leaky(num_filters, (3,3)))(x)
x = Add()([x,y])
return x
darknet框架
使用了resblock_body按照如图所示的框架搭建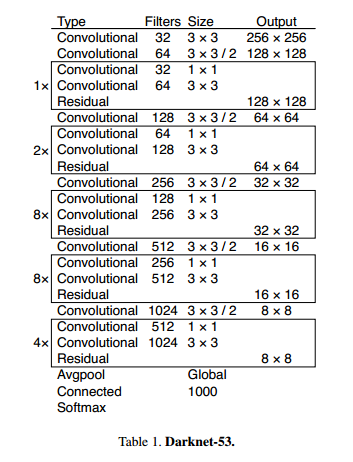
源码如下:1
2
3
4
5
6
7
8'''Darknent body having 52 Convolution2D layers'''
x = DarknetConv2D_BN_Leaky(32, (3,3))(x)
x = resblock_body(x, 64, 1)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)
x = resblock_body(x, 512, 8)
x = resblock_body(x, 1024, 4)
return x
由于每一次 resblock_body 中都含有一次步长为2的卷积,一共执行了5次,所以一共降维了 倍,因此最后的特征图大小就是 416 / 32 = 13
最后输出的网络中的 num_filter = 1024,输出结构是(sample_num, 13, 13, 1024)
yolo框架
make_last_layers(x, num_filters, out_filters)
在 yolo_body 中使用到了这个函数,主要用来进行输出的降维操作,共执行2步操作:
- 对 x 进行多次卷积操作,先将num_filters扩大一倍,再恢复原来的大小,最终输出的num_filters的到校仍是参数中的num_filters的大小
- 对 y 先进行 3 x 3 的卷积,再执行不含BatchNormalization和LeakyReLU的 1 x 1 卷积, 将输出的 num_filters 的大小降维out_filters
补充 1 x 1 卷积
- 1x1的卷积层可以灵活控制网络的depth也就是深度或者厚度,是对相同channel上的信息上的线性组合,从而达到降维\升维的目的,同时卷积之后特征图的大小没有变即在保持平面信息不变的情况下调整维度,所以 1 x 1 的卷积主要是针对网络的depth
- 1x1的卷积层在inception结构中还有降低计算量的作用
- 先了解多核卷积的实例计算:https://www.cnblogs.com/ranjiewen/articles/7467600.html(注意看黑体加粗的重点部分),学会如何计算多核卷几下的神经元个数
- 在此基础之上就可以理解下面这幅图了:
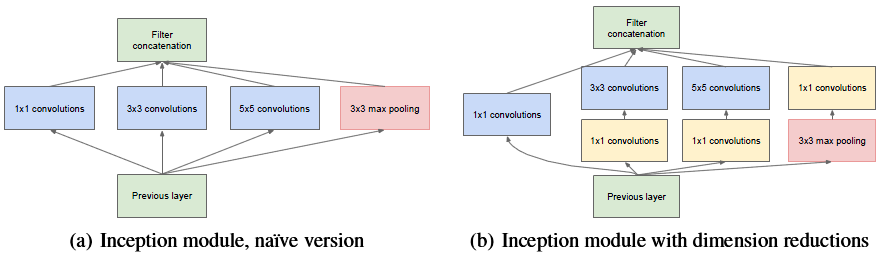
- 左边是传统的inception模块,右边是加入1x1 卷积的inception。这层的输入的特征维数是(28x28x192),卷积核大小以及卷积通道数(包括三种卷积核,分别是1x1x64,3x3x128,5x5x32),右图中在3x3,5x5 convolution前新加入的1x1的卷积核为 96 和 16 通道的,在max pooling后加入的1x1卷积为 32 通道。
- 那么图(a)的参数为(1x1x192x64)+(3x3x192x128)+(5x5x192x32)
- 图(b)的参数为(1x1x192x64)+(1x1x192x96)+(1x1x192x16)+(3x3x96x128)+(5x5x16x32)+(1x1x192x32).
比较可知,模型参数减少了。 - 参考:https://blog.csdn.net/a1154761720/article/details/53411365
yolo_body(inputs, num_anchors, num_classes)
参数:
- inputs: 输入张量
- num_anchors: 锚的数量
- num_classes: 类别的数量
输出: 一个以输入张量为输入,三个张量组合[y1,y2,y3]为输出的模型
13 x 13 特征图
先使用了darknet框架生成基本模型,将输出传给 make_last_layers ,将 x 的 num_filters 变为 512
输出的 x 的大小是 (sample_num, 13, 13, 512)
输出的 y1 的大小是(sample_num, 13, 13, num_anchors*(5 + num_classes))
26 x 26 特征图
接着将输出为(sample_num, 13, 13, 512) 的 x 进行上采样2倍(UpSampling2D(2)),并且num_filters 变为256,x 的大小变为 (sample_num, 26, 26, 256)
然后和 darknet 的第152层网络(sample_num, 26, 26, 512)进行连接,
生成大小为 (sample_num, 13, 13, 768)
最后使用 make_last_layers 将 num_filters 改为256,并输出y2
输出的 x 的大小是 (sample_num, 26, 26, 256)
输出的 y2 的大小是(sample_num, 26, 26, num_anchors*(5 + num_classes))
52 x 52 特征图
同样将输出为(sample_num, 26, 26, 256) 的 x 进行2倍的上采样,num_filters 变为 128, x 的大小变为(sample_num, 52, 52, 128)
然后和 darknet 的第92层网络(sample_num, 52, 52, 256)进行连接,
生成大小为 (sample_num, 13, 13, 384)
使用 make_last_layers 将 num_filters 改为128,并输出y3
输出的 x 的大小是 (sample_num, 52, 52, 128)
输出的 y3 的大小是(sample_num, 52, 52, num_anchors*(5 + num_classes))
最终,yolo框架输出的是三个大小不同的特征图
y1: (sample_num, 26, 26, num_anchors(5 + num_classes))
y2: (sample_num, 26, 26, num_anchors(5 + num_classes))
y3: (sample_num, 52, 52, num_anchors*(5 + num_classes))
源码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21"""Create YOLO_V3 model CNN body in Keras."""
darknet = Model(inputs, darknet_body(inputs))
# 13 x 13 特征图
x, y1 = make_last_layers(darknet.output, 512, num_anchors*(num_classes+5))
# 26 x 26 特征图
x = compose(
DarknetConv2D_BN_Leaky(256, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[152].output])
x, y2 = make_last_layers(x, 256, num_anchors*(num_classes+5))
# 52 x 52 特征图
x = compose(
DarknetConv2D_BN_Leaky(128, (1,1)),
UpSampling2D(2))(x)
x = Concatenate()([x,darknet.layers[92].output])
x, y3 = make_last_layers(x, 128, num_anchors*(num_classes+5))
return Model(inputs, [y1,y2,y3])
yolo_boxes_and_scores()
提取框_boxes和置信度_box_scores
yolo_eval()
anchor_mask : anchor的掩码,由于anchor文件中是按从小到大排列的,而model.output输出的层是 13->52 ,而越小的特征图检测的是越大的物体,也就需要越大的anchor,所以anchor_mask 是倒叙排列
使用yolo_boxes_and_scores获得提取框_boxes和置信度_box_scores
然后使用非极大抑制算法筛选标注框
再使用 K.gather 通过nms_index筛选合格的框和框对应得分
1 | boxes_ = K.concatenate(boxes_, axis=0) |
// tf.gather 使用实例: https://blog.csdn.net/guotong1988/article/details/53172882
使用 K.ones_like x c 生成类别信息, 例:[1,1,1] x 4 = [4,4,4] 代表3个类别为4的框
最后使用 K.concatenate 合并所有的框,合并所有的得分,合并所有的的类别信息
补充涉及的小细节
1.非极大抑制算法
在 yolo_eval() 中用到了 非极大抑制算法
非极大抑制算法(NMS):用来剔除重合度高于阈值的框,有时候可能会有多个框检测的是同一个物体
首先从所有的检测框中找到置信度较大的那个框,然后挨个计算其与剩余框的IOU,如果其值大于一定阈值(重合度过高),那么就将该框剔除;然后对剩余的检测框重复上述过程,直到处理完所有的检测框
1 | # 使用方法 |
2.concatenate
concatenate 的使用:concatenate将相同维度的数据元素连接到一起
例:1
2
3
4
5
6
7
8
9
10
11
12
13from keras import backend as K
sess = K.get_session()
a = K.constant([[2, 4], [1, 2]])
b = K.constant([[3, 2], [5, 6]])
c = [a, b]
c = K.concatenate(c, axis=0)
print(sess.run(c))
"""
[[2. 4.] [1. 2.] [3. 2.] [5. 6.]]
"""
损失函数
等待更新….

